DeepLab v2
DeepLab
v1 VS v2
* 공통점: 모두 atrous convolution 과 fully connected CRF를 사용했다는 공통점이 있다.
* 차이점: v2에서 multiple-scale에 대한 처리방법이 개선되었고(ASPP) Vgg-16 대신 resnet-101을 기본 망으로 사용해서 성능을 개선시킴.
(V1 71.6% IOU -> v2 79.7%)
DeepLab v2
Semantic segmentation과 같은 dene prediction task는 픽셀 단위의 예측이 필요해서 Classification net으로 segmentation net을 구성하면 feature map의 크기가 줄어들기 때문에 detail 정보를 얻는데 어려움이 있음. 그래서 net의 뒷 단에 있는 2개의 pooling layer를 제거하고 atrous convolution을 사용해 receptive field를 확장시키고 1/8 크기까지만 feature map을 줄여 detail 정보 사라지는 것을 커버함.
그럼에도 문제가 있는데 바로 receptive field가 충분히 크지 않아서 다양한 scale에 대응이 어렵다는 것.
-> 해결: ASPP (Astrous Spatial Pyramid Pooling)
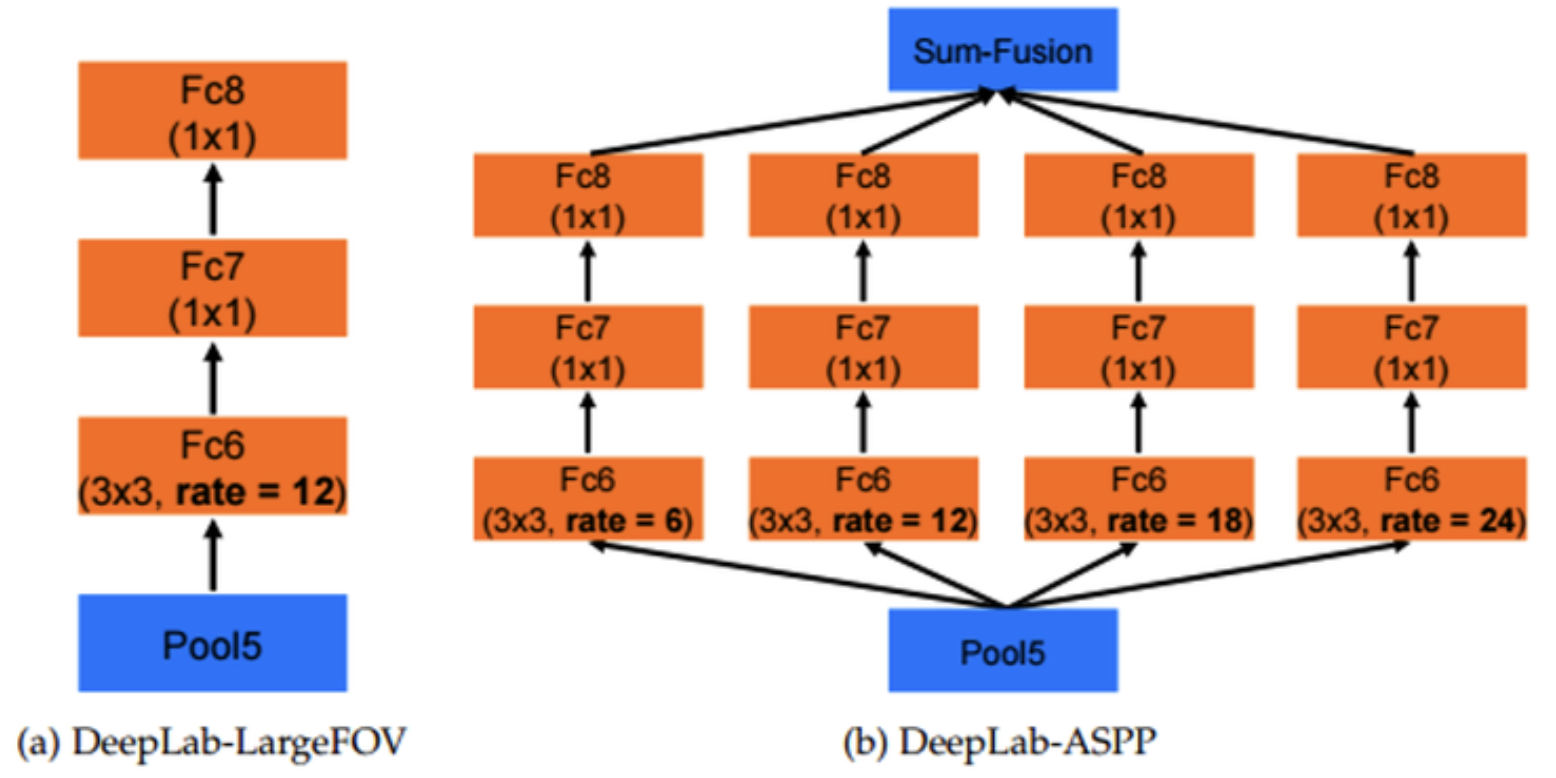
ASPP (Astrous Spatial Pyramid Pooling)
여러가지 rate를 가진 atrous convolution(=dilated convolution)을 합쳐 다양한 크기의 object와 image context 정보를 알 수 있다.
Deeplab v1과 달리 v2에서는 multi-scale에 더 잘 대응할 수 있도로 fc6 layer에서 atrous convolution을 위한 확장 계수를 {6,12,18,24}로 적용하고 그 결과를 취합해 사용했다고 한다.

이렇게 확장 계수를 6에서 24로 변화시킴으로써 다양한 receptive field를 볼 수 있게 되었음.
또, 논문의 실험에 따르면 단순하게 fc6 layer의 확장 계수를 12로 고정하는 것(a)보다 이렇게 ASPP를 사용함(b)으로써 약 1.7% 정도 성능을 개선할 수 있다고 한다.
DeepLab v2 구조
전체적인 구조는 DCNN (deep convolution neural network) + CRF(conditional Random Field) 형태이고 DCNN의 앞부분은 일반적인 convolutioin을 사용하고 뒷부분은 atrous convolution(일명 hole algorithm)을 수행함.

DCNN을 통해 input의 1/8 크기의 coarse score-map을 구하고 이것을 bilinear interpolation을 통해 원래 크기로 확대시킴. bilinear interpolation을 통해 얻어진 결과는 각 pixel위치에서의 label에 대한 확률이 되며 fully connected CRF 후보정 작업을 통해 최종적인 결과를 얻는다.
참고